[推荐算法]ItemCF,基于物品的协同过滤算法
ItemCF:ItemCollaborationFilter,基于物品的協同過濾
算法核心思想:給用戶推薦那些和他們之前喜歡的物品相似的物品。
比如,用戶A之前買過《數據挖掘導論》,該算法會根據此行為給你推薦《機器學習》,但是ItemCF算法并不利用物品的內容屬性計算物品之間的相似度,它主要通過分析用戶的行為記錄計算物品之間的相似度。
==>該算法認為,物品A和物品B具有很大的相似度是因為喜歡物品A的用戶大都也喜歡物品B。
基于物品的協同過濾算法主要分為兩步:
二、根據物品的相似度和用戶的歷史行為給用戶生成推薦列表;
下面分別來看這兩步如何計算:
一、計算物品之間的相似度:
我們使用下面的公式定義物品的相似度:
其中,|N(i)|是喜歡物品i的用戶數,|N(j)|是喜歡物品j的用戶數,|N(i)&N(j)|是同時喜歡物品i和物品j的用戶數。
從上面的定義看出,在協同過濾中兩個物品產生相似度是因為它們共同被很多用戶喜歡,兩個物品相似度越高,說明這兩個物品共同被很多人喜歡。
這里面蘊含著一個假設:就是假設每個用戶的興趣都局限在某幾個方面,因此如果兩個物品屬于一個用戶的興趣列表,那么這兩個物品可能就屬于有限的幾個領域,而如果兩個物品屬于很多用戶的興趣列表,那么它們就可能屬于同一個領域,因而有很大的相似度。
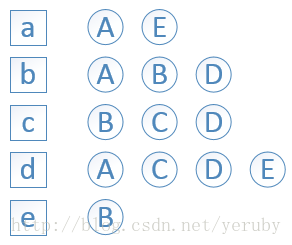
舉例,用戶A對物品a、b、d有過行為,用戶B對物品b、c、e有過行為,等等;

依此構建用戶——物品倒排表:物品a被用戶A、E有過行為,等等;
建立物品相似度矩陣C:
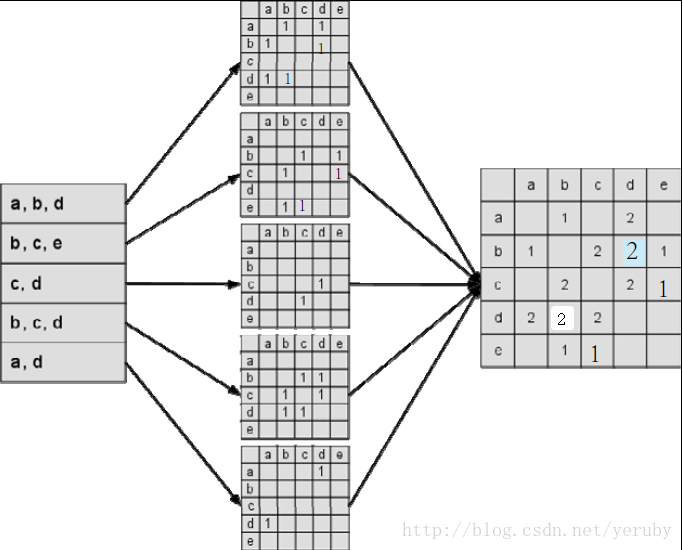
其中,C[i][j]記錄了同時喜歡物品i和物品j的用戶數,這樣我們就可以得到物品之間的相似度矩陣W。
在得到物品之間的相似度后,進入第二步。
二、根據物品的相似度和用戶的歷史行為給用戶生成推薦列表:
ItemCF通過如下公式計算用戶u對一個物品j的興趣:

其中,Puj表示用戶u對物品j的興趣,N(u)表示用戶喜歡的物品集合(i是該用戶喜歡的某一個物品),S(i,k)表示和物品i最相似的K個物品集合(j是這個集合中的某一個物品),Wji表示物品j和物品i的相似度,Rui表示用戶u對物品i的興趣(這里簡化Rui都等于1)。
該公式的含義是:和用戶歷史上感興趣的物品越相似的物品,越有可能在用戶的推薦列表中獲得比較高的排名。
下面是一個書中的例子,幫助理解ItemCF過程:
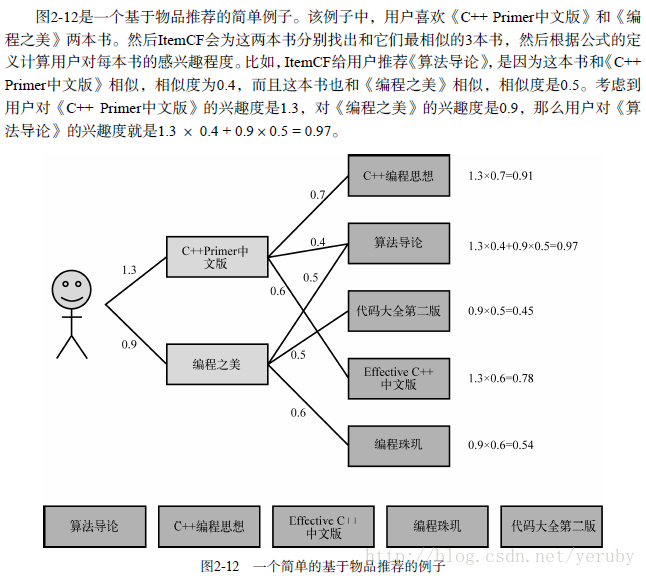
至此,基礎的ItemCF算法小結完畢。
下面是書中提到的幾個優化方法:
(1)、用戶活躍度對物品相似度的影響
即認為活躍用戶對物品相似度的貢獻應該小于不活躍的用戶,所以增加一個IUF(Inverse User Frequence)參數來修正物品相似度的計算公式:
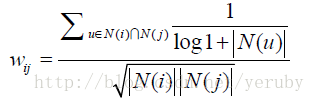
用這種相似度計算的ItemCF被記為ItemCF-IUF。
ItemCF-IUF在準確率和召回率兩個指標上和ItemCF相近,但它明顯提高了推薦結果的覆蓋率,降低了推薦結果的流行度,從這個意義上說,ItemCF-IUF確實改進了ItemCF的綜合性能。
(2)、物品相似度的歸一化
Karypis在研究中發現如果將ItemCF的相似度矩陣按最大值歸一化,可以提高推薦的準確度。其研究表明,如果已經得到了物品相似度矩陣w,那么可用如下公式得到歸一化之后的相似度矩陣w':
最終結果表明,歸一化的好處不僅僅在于增加推薦的準確度,它還可以提高推薦的覆蓋率和多樣性。
用這種相似度計算的ItemCF被記為ItemCF-Norm。
————————————————
版權聲明:本文為CSDN博主「qwurey」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/yeruby/article/details/44154009
算法核心思想:給用戶推薦那些和他們之前喜歡的物品相似的物品。
比如,用戶A之前買過《數據挖掘導論》,該算法會根據此行為給你推薦《機器學習》,但是ItemCF算法并不利用物品的內容屬性計算物品之間的相似度,它主要通過分析用戶的行為記錄計算物品之間的相似度。
==>該算法認為,物品A和物品B具有很大的相似度是因為喜歡物品A的用戶大都也喜歡物品B。
基于物品的協同過濾算法主要分為兩步:
一、計算物品之間的相似度;
二、根據物品的相似度和用戶的歷史行為給用戶生成推薦列表;
下面分別來看這兩步如何計算:
一、計算物品之間的相似度:
我們使用下面的公式定義物品的相似度:
其中,|N(i)|是喜歡物品i的用戶數,|N(j)|是喜歡物品j的用戶數,|N(i)&N(j)|是同時喜歡物品i和物品j的用戶數。
從上面的定義看出,在協同過濾中兩個物品產生相似度是因為它們共同被很多用戶喜歡,兩個物品相似度越高,說明這兩個物品共同被很多人喜歡。
這里面蘊含著一個假設:就是假設每個用戶的興趣都局限在某幾個方面,因此如果兩個物品屬于一個用戶的興趣列表,那么這兩個物品可能就屬于有限的幾個領域,而如果兩個物品屬于很多用戶的興趣列表,那么它們就可能屬于同一個領域,因而有很大的相似度。
舉例,用戶A對物品a、b、d有過行為,用戶B對物品b、c、e有過行為,等等;
依此構建用戶——物品倒排表:物品a被用戶A、E有過行為,等等;
建立物品相似度矩陣C:
其中,C[i][j]記錄了同時喜歡物品i和物品j的用戶數,這樣我們就可以得到物品之間的相似度矩陣W。
在得到物品之間的相似度后,進入第二步。
二、根據物品的相似度和用戶的歷史行為給用戶生成推薦列表:
ItemCF通過如下公式計算用戶u對一個物品j的興趣:
其中,Puj表示用戶u對物品j的興趣,N(u)表示用戶喜歡的物品集合(i是該用戶喜歡的某一個物品),S(i,k)表示和物品i最相似的K個物品集合(j是這個集合中的某一個物品),Wji表示物品j和物品i的相似度,Rui表示用戶u對物品i的興趣(這里簡化Rui都等于1)。
該公式的含義是:和用戶歷史上感興趣的物品越相似的物品,越有可能在用戶的推薦列表中獲得比較高的排名。
下面是一個書中的例子,幫助理解ItemCF過程:
至此,基礎的ItemCF算法小結完畢。
下面是書中提到的幾個優化方法:
(1)、用戶活躍度對物品相似度的影響
即認為活躍用戶對物品相似度的貢獻應該小于不活躍的用戶,所以增加一個IUF(Inverse User Frequence)參數來修正物品相似度的計算公式:
用這種相似度計算的ItemCF被記為ItemCF-IUF。
ItemCF-IUF在準確率和召回率兩個指標上和ItemCF相近,但它明顯提高了推薦結果的覆蓋率,降低了推薦結果的流行度,從這個意義上說,ItemCF-IUF確實改進了ItemCF的綜合性能。
(2)、物品相似度的歸一化
Karypis在研究中發現如果將ItemCF的相似度矩陣按最大值歸一化,可以提高推薦的準確度。其研究表明,如果已經得到了物品相似度矩陣w,那么可用如下公式得到歸一化之后的相似度矩陣w':
最終結果表明,歸一化的好處不僅僅在于增加推薦的準確度,它還可以提高推薦的覆蓋率和多樣性。
用這種相似度計算的ItemCF被記為ItemCF-Norm。
————————————————
版權聲明:本文為CSDN博主「qwurey」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/yeruby/article/details/44154009