人工智能之自然语言处理初探

最近在梳理人工智能的一個細分領域自然語言處理相關知識點。隨著查閱的資料越來越多,在梳理的過程中,也越來越發現自己的無知。雖然自然語言處理是人工智能的一個細分領域,但是自然語言處理這個細分領域內,又有很多的細分領域。自然語言處理,也是涵蓋了多個學科的一個系統化的大型工程。自然語言處理,除了包含常見的分詞、分句、分段,詞目計算、詞類標注,有限狀態自動機、隱馬爾可夫模型等基礎的計算機理論知識外,還包含了語音學、語言學、心理學、統計學、腦科學等多個領域的學科知識。一個人不可能把自然語言處理所有的知識都全部掌握精通,也只能是找到其中的一個或幾個難點進行研究。今天文章題目定為《人工智能之自然語言處理初探》,似乎題目也是有點過大了。所以又取了一個子題目,叫“語義識別”。即便是這樣,在今天有限的文章描述以及PPT演示,也難以涵蓋語義識別這個領域的全部內容。

今天的文章以PPT為主線,受制于時間限制以及這個領域內容的確非常多非常深,即便是潛心鉆嚴三年,是否能真正就說掌握了自然語言處理的語義分析,誰也不敢保證。進無止境。這恐怕也是科學的魅力。本文今天主要分為六個章節,第一章節先對自然語言處理進行簡要介紹。主要對自然語言處理(Natural Language Processing, 下文會以NLP替代。)的苦命分類進行概要介紹。同時介紹一下NLP在文本和語音兩個方面的商業應用。第二章節從發現歷程、參與的公司以及行業規模,介紹當前NLP發展現狀。第三章,對整個NLP體系進行梳理。第四、五、六章節主要對NLP中語義識別中的句法分析、話語分割、指代消解的基礎原理進行講述。
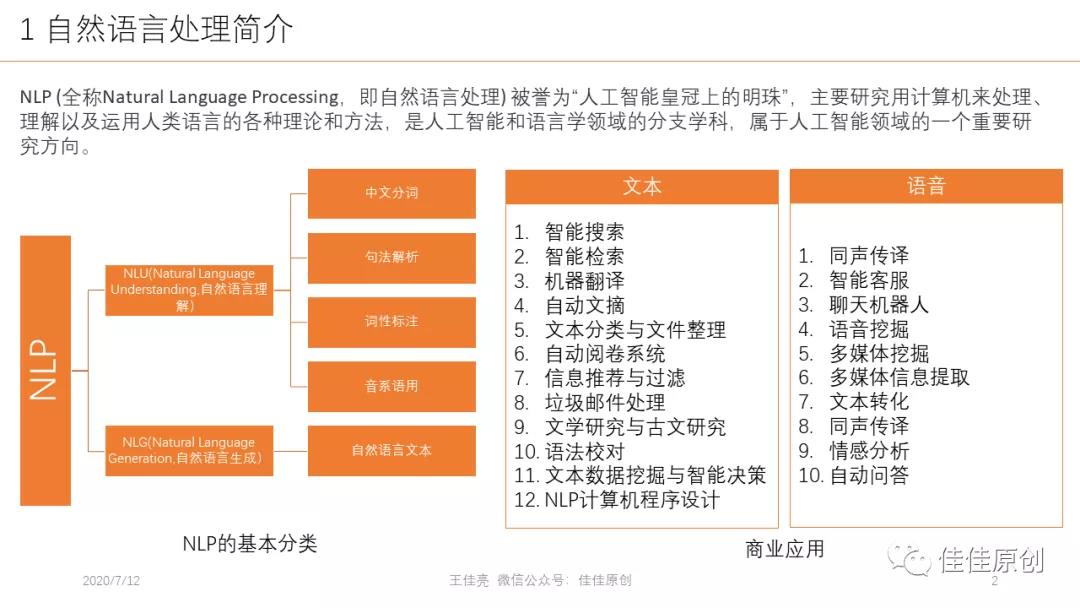
自然語言的理解層次,一般分為:語音分析、詞法分析、句法分析、語義分析、語用分析。簡單來講,語音分析主要是根據音位規則,從語音流中提取出獨立的音素,再根據音位形態規則找出音節及其所對應的單詞;詞法分析主要是找出詞匯中的詞素,從而獲得其語音學的信息;句法分析,則是對句子和句子中的短語結構進行分析,發現其內存的關聯關系;語義分析是要找出單詞、結構,通過結合上下文,獲得準確的含義;語用分析,則是研究語言所處在的實際語言環境中對語言使用者所產生的實際作用。
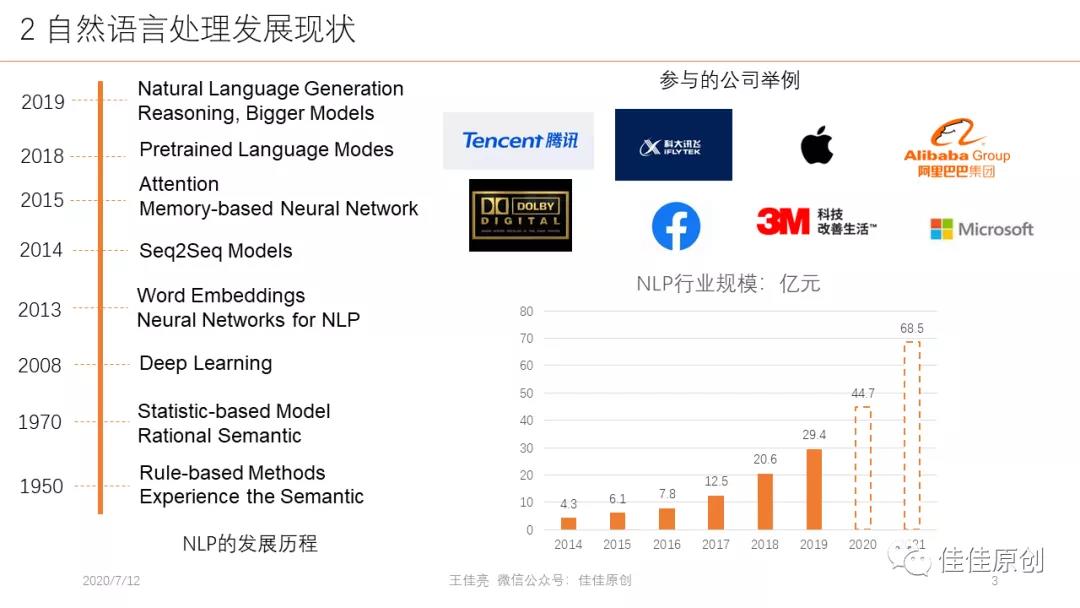
1950:圖靈測試、經驗語義方法、基于規則的方法。
1970:基于統計的方法、理性語義方法。2008年:深度學習。
2013年,Word Embeddings(Word2Vec),即將高維詞向量嵌入到一個低維空間,Neural Networks for NLP(RNN LSTM CNN)。
2014年,Seq2Seq Models,Seq2Seq模型是輸出的長度不確定時采用的模型;MachineTranslation, Structure Prediction。2015年,Attention,把一個輸入序列表示為連續序列,解碼生成一個輸出序列,模型每一步都是自回歸的,即假設之前生成的結果都是作為生成下一個符號的額外輸入;Transformer,直接把一句話當做一個矩陣進行處理。
2018年,Memory-based Neural Network, NeuralTuringMachine。2018m, Pretrained Language Modes, ELMo,BERT。
2019年,Natural Language Generation,Reasoning, Bigger Models。
自然語言處理(NLP)正處于歷史上最好的發展時期,技術在不斷進步并與各個行業不斷融合、落地。數據顯示,我國NLP(自然語言處理)技術市場規模持續增長,2018年我國NLP(自然語言處理)技術市場規模達到了20.6億元,同比增長52.6%。未來隨著NLP技術不斷進步,將具有大規模的市場需求和可擴展的巨大市場空間。預計2021年市場規模將達到近70億元。
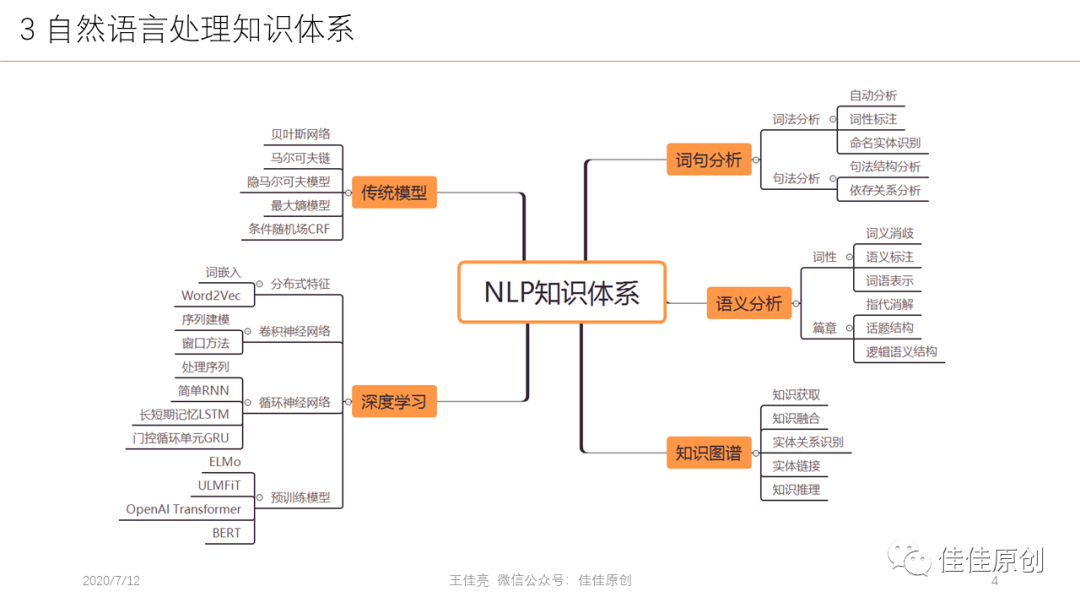
NLP整個知識體系非常多。研究模式主要是對自然語言場景問題,算法如何應用到解決這些問題。即便是涉及如此多的基礎知識,目前NLP仍然面臨著許多的問題,例如:場景的困難,語言的多樣性、多變性、歧義性,使得NLP準確性受到制約。學習的困難,如何設計高效的學習模型?語料的困難,NLP應該使用什么樣的語料?如何獲得這些語料?

對于語義識別,需要對句法進行剖析,因此剖析在問答系統、信息抽取、語法檢查中都起著非常重要的作用。1954年1月7日,美國喬治敦大學和IBM公司首先成功地將60多句俄語自動翻譯成英語。當時的系統還非常簡單,僅包含6個語法規則和250個詞。而實驗者聲稱:在三到五年之內就能夠完全解決從一種語言到另一種語言的自動翻譯問題。但直到今天,自然語言處理別說是自動翻譯,簡單的句法分析仍然有很多要完善的空間。“咬死了獵人的狗。”究竟是“[咬死了獵人][的狗]”還是“[咬死了][獵人的狗]”呢?如果不借助于上下文和語境,即便是人都很難理解,更不用說使用的句法分析了。

我們通過計算,可以增加句法分析的準確性。但是否能真實反應語義,仍然有很大的發展空間。

我們可以計算布朗預料庫中每個句子的平均詞數。在其他情況下,文本可能只是一個字符流。在將文本分詞之前,需要將它分割成句子。有時可以借助于標點體符號以及一些典型的計算機符號,例如換行符來進行對句子分隔,但對于沒有任何標點符號的文字段落來講,人類可以借助經驗理解里面的內容,NLP是否也能準備分割,也是比較難的一個研究領域,還有很大的發展空間。

指代消解是NLP里非常重要的一個細分的研究領域,應用場景非常多。例如智能對話預定酒店機票,“從天津到北京的機票多少錢?” 計算機NLP后,給出一個結果,這個時候,再問“那到上海呢?”,這個就需要NLP有更深層的理解了。而現實中的對話場景,遠比這個要復雜的多,NLP是否能準確識別,就依賴于指代消解的準確度了。這直接關系到NLP的產品質量。
總結:
今天主要是對NLP中的語義識別的一個領域進行初步探索。人工智能是一個非常大的范疇,即便人工智能的子領域NLP,涉及的基礎研究也非常多,而且這些基礎研究短時間內也很難見效,很多公司都有業績壓力,往往出于收益,即便不是一個很完善的NLP產品,也先要推向市場。不論是NLP應用在哪個領域,構建什么樣的產品,解決什么樣的現實問題,根本還是要依賴于基礎科技的研究,一個個豐富多彩的NLP產品,都是由一個個基礎功能整合而成。正所謂,不積跬步無以至千里,不積小流無以成江海。